Key takeaways and insights from the EDPB Pseudonymisation Guidelines
On 16 January, 2025, the EDPB released its guidelines on pseudonymisation. These guidelines are not yet finalized, as they remain open for public consultation until 28 February. Notably, they are more technical and complex compared to earlier guidelines. Below, we highlight the key takeaways.

What is pseudonymisation and how does it work?
Back to basics
- Definition: The concept of pseudonymisation is defined in Article 4(5) of the GDPR as “processing of personal data in such a manner that the personal data can no longer be attributed to a specific data subject without the use of additional information, provided that such additional information is kept separately and is subject to technical and organisational measures to ensure that the personal data are not attributed to an identified or identifiable natural person”.
- Pseudonymised data is personal data: Pseudonymisation should not be confused with anonymisation. Pseudonymised data remains personal data, whereas anonymised data is not considered personal data and, as a result, falls outside the scope of the GDPR.
Key takeaways from the guidelines
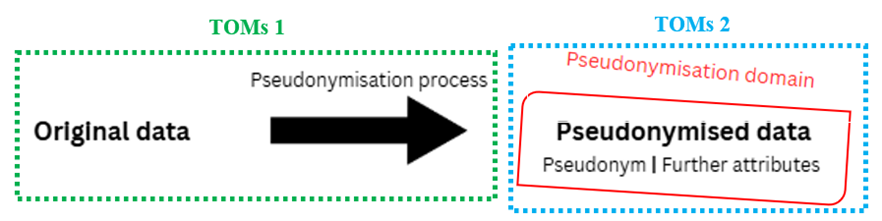
Pseudonymisation in the legal sense generally requires three actions:
1. Pseudonymisation process: Pseudonymise the data, i.e. modify of transform the original data so that it becomes pseudonymised, i.e. so that it is no longer possible to attribute the pseudonymised data to a specific data subject without additional information. Pseudonymisation should at least concern direct identifiers (e.g. passport or social security numbers, but also the combination of the full name of a person with his or her date of birth) which, alone, allow to identify data subjects. The pseudonymising entity should also be mindful of indirect identifiers (e.g. by deleting such indirect identifiers, generalising or randomising them), which may also allow to identify a data subject despite the pseudonymisation.
This first action (pseudonymisation) generally consists in a table matching pseudonyms with some identifying attributes (lookup tables), or in cryptographic techniques (e.g. message authentication codes or “MACs”1, or encryption algorithms).
⚠ If your original data only concerns 10 persons (for instance) within a company, and you simply replace their full name by their initials, this does not amount to pseudonymisation in the legal sense, since there would be no need to have additional information in order to make the link between the initial and the person behind it.
⚠ We also emphasize that, in the legal sense, pseudonymisation does not require the use of pseudonyms.
2. Separation: Keep additional information (that would allow an entity to attribute the pseudonymised data to a data subject) separate from the pseudonymised data.
This additional information includes in particular the original data, but also the pseudonymisation process. Indeed, if a person was to know the details of the pseudonymisation process, this person would often be able to deduct the original data from the pseudonym.
3. TOMs : Implement technical and organisational measures, in particular to protect the separation of the additional information (TOMs 1), but also to protect the pseudonymised data (so that they do not inappropriately leave the pseudonymisation domain ; TOMs 2). TOMs include:
- Network segmentation (i.e. dividing a network into sub-networks that are hermetic, at least to a certain extent);
- Store secret keys in hardware security modules (i.e. a secure device that stores and manages secret keys);
- Secure authentication for Application Programming Interface (API) access;
- Rate limiting2 and logging of the execution of the pseudonymising transformation and its reverse application;
- employment of specifically authorised personnel to perform and manage the pseudonymisation process;
- Training of employees.
These actions lead to what the EDPB calls a pseudonymisation domain, i.e. a domain within which the people only process pseudonymised data, and have no access to the additional information allowing them to link the pseudonymised data with a data subject. The people within the pseudonymisation domain can be part of the organisation which has pseudonymised the data, or can be external data recipients. The EDPB also recommends to take unauthorised recipients (e.g. hackers) into account. This pseudonymisation domain should be protected by TOMs, amongst others to make sure that the additional information that would allow to make the link with the data subject does not enter the pseudonymisation domain.
Advantages of pseudonymisation
Pseudonymisation offers a series of well-known advantages such as : respect the data protection by default and by design principles, securing the personal data, etc.
Next to these well-known advantages, we want to emphasise two other advantages that are often overlooked:
1. Rely on legitimate interests: The legitimate interest criterion is one of the most important legal basis to process personal data, as the other legal bases are often inapplicable. However, it requires a balancing exercise between the rights of the data subject and the rights of the controller. Pseudonymisation may help to tip the scales in the controller’s favour, as it diminishes the risks to the rights and freedoms of data subjects.
2. International data transfers: Pseudonymisation may be an appropriate supplementary measure (in the sense of C-311/18 Schrems II) to be combined with standard contractual clauses (SCCs) or binding corporate rules (BCRs) to legitimate an international data transfer that would otherwise not secure an essentially equivalent level of protection.
Of course, this entails that the foreign public authorities would only have access to the pseudonymised data, and not to the additional information.
This blog post only provides a summary of some of the points made in the EDPB guidelines. It should not be considered legal advice and is not intended to reflect all nuances or aspects of the guidelines.
- 1Message authentication codes or “MACs” are similar to hash functions, except that they also implement a secret key, so that they are a stronger pseudonymisation technique than a simple hash function. In a nutshell, hashing is a process used to transform an input (for instance the name of a person, or a picture) into an output that is composed of a set of characters with a fixed length (g6q7f8, for example) by way of a function. A key feature of such a process is that it is considered to be unidirectional, so that one cannot, as a principle, derive the input from the output.
- 2Rate limiting ensures that a service keeps working even under high traffic conditions, amongst others to avoid denial of service attacks.

